Replicate a Database
OSO's dagster infrastructure has support for database replication into our data warehouse by using Dagster's "embedded-elt" that integrates with the library dlt.
Configure your database as a dagster asset
There are many possible ways to configure a database as a dagster asset, however, to reduce complexity of configuration we provide a single interface for specifying a SQL database for replication. The SQL database must be a database that is supported by dlt. In general, we replicate all columns and for now custom column selection is not available in our interface.
This section shows how to setup a database with two tables as a set of sql
assets. The table named some_incremental_database has a chronologically
organized or updated dataset and can therefore be loaded incrementally. The
second table, some_nonincremental_database, does not have a way to be loaded
incrementally and will force a full refresh upon every sync.
To setup this database replication, you can add a new python file to
warehouse/oso_dagster/assets. This file will have the following contents:
from oso_dagster.factories.sql import sql_assets
from oso_dagster.utils.secrets import SecretReference
from dlt.sources import incremental
my_database = sql_assets(
"my_database", # The asset prefix for this asset. This is the top level name of the asset.
# You can think of this as the folder for the asset in the dagster UI
SecretReference(
group_name="my_group", # In most cases this should match the asset prefix
key="db_connection_string" # A name you'd like to use for the secret.
),
[
{
"table": "some_time_series_database",
"incremental": incremental("time")
},
{
"table": "some_non_time_series_database",
},
],
)
The first three lines of the file import some necessary tooling to configure a sql database:
- The first import,
sql_assets, is an asset factory created by the OSO team that enables this "easy" configuration of sql assets. - The second import,
SecretReference, is a tool used to reference a secret in a secret resolver. The secret resolver can be configured differently based on the environment, but on production we use this to reference a cloud based secret manager. - The final import,
incremental, is used to specify a column to use for incremental loading. This is adltconstructor that is passed to the configuration.
The sql_assets, factory takes 3 arguments:
-
The first argument is an asset key prefix which is used to both specify an asset key prefix and also used when generating asset related names inside the factory. In general, this should match the filename of the containing python file unless you have a more complex set of assets to configure. This name is also used as the dataset name into which this data will be loaded.
-
The second argument must be a
SecretReferenceobject that will be used to retrieve the credentials that you will provide at a later step to the OSO team. TheSecretReferenceobject has two required keyword arguments:group_name- Generally this should be the same as the asset key prefix. This is an organizational key for the secret manager to use when locating the secrets.key- This is an arbitrary name for the secret.
-
The third argument is a list of dictionaries that define options for tables that should be replicated into the data warehouse. The most important options here are:
table- The table namedestination_table_name- The table name to use in the data warehouseincremental- Anincrementalobject that defines time/date based column to use for incrementally loading a database.
Other options exist but full documentation is out of scope for this guide. For more information, see the
sql_tablefunction inside the python package located atwarehouse/oso_dagster/dlt_sources/sql_databaseof the repository.
Enabling access to your database
Before the OSO infrastructure can begin to synchronize your database to the data warehouse, it will need to be provided access to the database. At this time there is no automated process for this. Once you're ready to get your database integrated, you will want to contact the OSO team on our Discord. Be prepared to provide credentials (we will work out a secure method of transmission) and also ensure that you have access to update any firewall settings that may be required for us to access your database server.
Add the asset to the OSO Dagster configuration
Submit a pull request
When you are ready to deploy, submit a pull request of your changes to OSO. OSO maintainers will work with you to get the code in shape for merging. For more details on contributing to OSO, check out CONTRIBUTING.md.
Verify deployment
Our Dagster deployment should automatically recognize the asset after merging your pull request to the main branch. You should be able to find your new asset in the global asset list.
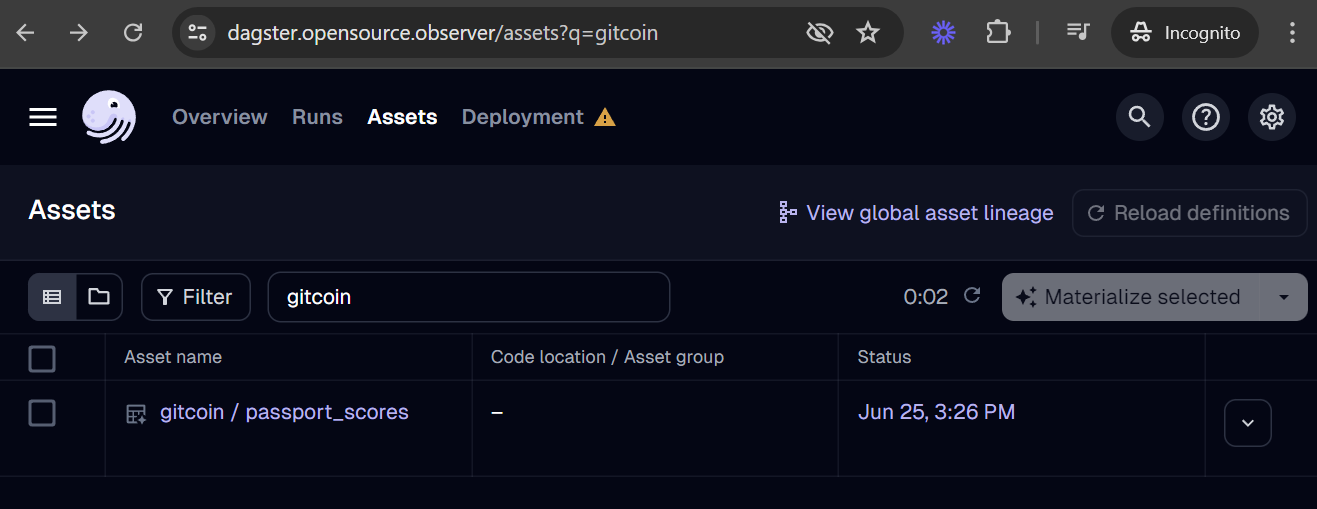
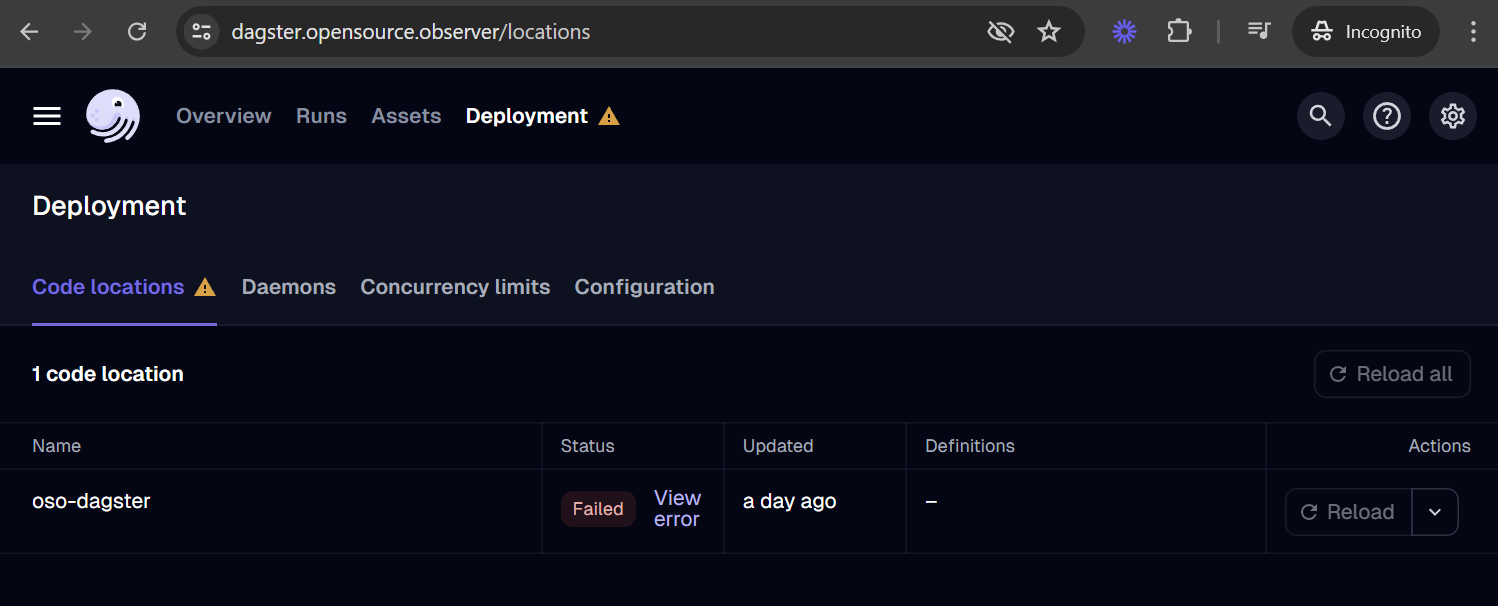
If your asset is missing, you can check for loading errors and the date of last code load in the Deployment tab. For example, if your code has a bug and leads to a loading error, it may look like this:
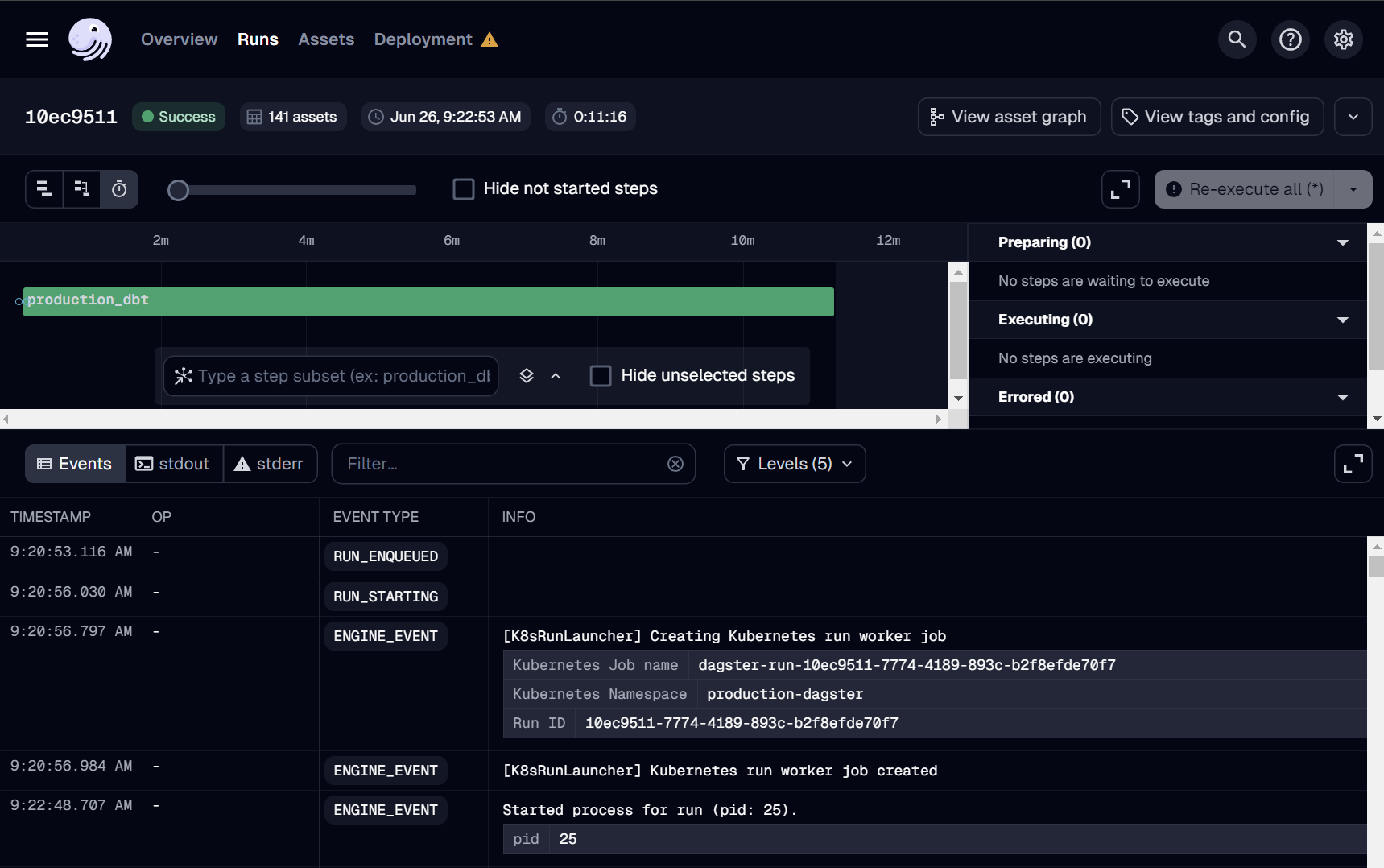
Run it!
If this is your first time adding an asset, we suggest reaching out to the OSO team over Discord to run deploys manually. You can monitor all Dagster runs here.
Dagster also provides automation to run jobs on a schedule (e.g. daily), after detecting a condition using a Python-defined sensor (e.g. when a file appears in GCS), and using auto-materialization policies.
We welcome any automation that can reduce the operational burden in our continuous deployment. However, before merging any job automation, please reach out to the OSO devops team on Discord with an estimate of costs, especially if it involves large BigQuery scans. We will reject or disable any jobs that lead to increased infrastructure instability or unexpected costs.
Defining a dbt source
In order to make the new dataset available to the data pipeline,
you need to add it as a dbt source.
In this example, we create a source in oso/warehouse/dbt/models/
(see source)
for the Ethereum mainnet
public dataset.
sources:
- name: ethereum
database: bigquery-public-data
schema: crypto_ethereum
tables:
- name: transactions
identifier: transactions
- name: traces
identifier: traces
We can then reference these tables in downstream models with
the source macro:
select
block_timestamp,
`hash` as transaction_hash,
from_address,
receipt_contract_address
from {{ source("ethereum", "transactions") }}
Next steps
- SQL Query Guide: run queries against the data you just loaded
- Connect OSO to 3rd Party tools: explore your data using tools like Hex.tech, Tableau, and Metabase
- Write a dbt model: contribute new impact and data models to our data pipeline