Crawl an API
We expect one of the most common forms of data connection would be to connect some public API to OSO. We have created tooling to make this as easy as possible.
This workflow relies on a toolset called dlt. Simply, the dlt library provides a set of tools to make connecting data sources to a warehouse (or any other destination) very simple. There is a bit of complexity in configuring many of the aspects of dlt to write to the final destination so we've provided some helper functions and factories for you to concentrate on simply write a proper dlt source that crawls the api.
dlt overview
Before you start writing your own API crawler, it's important to understand some of the key concepts of DLT. We highly suggest that you read the dlt docs as they give a more thorough introduction. The outline here is simply an overview to get you to a very basic level of understanding.
DLT Concepts
The main concepts we will care about from DLT are:
- Resource
- A resource should be thought of as the collection of data for a single table. The majority of the code that is needed to collect data from some data source would be located in this resource.
- Source
- A Source is a collection of resources. In something like postgres, you might think of this as a schema or a dataset in bigquery.
- Destination
- While you shouldn't be creating your own destination when adding to OSO, this concept is as it sounds, it's the final place you'd like to have your collected source stored.
- Pipeline
- The pipeline orchestrates the flow of data from the source to the destination. In general, our tools have abstracted this away as well. So you likely won't need to interact directly with it.
DLT and Dagster
Dagster has 1st party support for integrating dlt as an asset. However, the
provided tools still require quite a bit of boiler plate configuration. In
response to this, we have created a set of tooling in our oso_dagster library
that should remove the need to understand or even interact with the initial
boilerplate.
Create DLT Dagster Assets
With the tooling in oso_dagster, writing a DLT asset for our dagster
deployment involves just writing a DLT Resource and using
oso_dagster's dlt_factory decorator to wire it together.
Basic Example
The following is a simple example that uses an example derived from dlt's docs
# This file should be in warehouse/oso_dagster/assets/name_of_asset_group.py
import dlt
from dlt.sources.helpers.rest_client import RESTClient
from dlt.sources.helpers.rest_client.paginators import JSONResponsePaginator
from pydantic import BaseModel
from oso_dagster.factories import dlt_factory, pydantic_to_dlt_nullable_columns
poke_client = RESTClient( # (1)
base_url="https://pokeapi.co/api/v2",
paginator=JSONResponsePaginator(next_url_path="next"),
data_selector="results",
)
class Pokemon(BaseModel): # (2)
name: str
url: str
@dlt.resource( # (3)
name="pokemon",
columns=pydantic_to_dlt_nullable_columns(Pokemon),
)
def get_pokemons():
for page in poke_client.paginate(
"/pokemon",
params={
"limit": 100,
},
):
for pokemon in page.results:
yield pokemon
@dlt_factory() # (4)
def pokemon():
yield get_pokemons()
The example has quite a few parts so we've added numbered sections to assist in explanation.
- Here we initialize a global client for the pokeapi that
uses DLT's provided
RESTClient. TheRESTCLientis a wrapper around the popularrequestslibrary. For more details on this, see the dlt docs on the subject. - A pydantic Model that is derived from the
pydantic.BaseModel. This model is used to derive the schema for the data generated from a dlt resource. This will later be used when configuring the dlt resource in section(3). - The DltResource. This is where the majority of logic should go
for crawling any API in question. As depicted here, the dlt resource is
created by using the
@dlt.resourcedecorator. While not strictly necessary to define a dlt resource, we require that you provide a schema in the argumentcolumnsthat matches the objects you wish to store in the data warehouse. This is generated from the pydantic model in(2). Additionally, we use a functionpydantic_to_dlt_nullable_columnsto ensure that all of the columns when written to the datawarehouse are nullable. This allows dlt to better automatically handle schema changes in the future. If you do not want to use nullable columns, you can discuss with us in a PR as to why that might be and we can offer alternative implementations. - The asset definition. This is the simplest form of asset that one can define
using the
@dlt_factorydecorator. The expected return type of a function decorated by@dlt_factoryisIterable[DltResource]. In more complicated use cases as you will see in the next example, this can be used to wire any dependencies required by the resource function.
Using Secrets with APIs
Often an API will need some form of authentication. In such a case, the authentication secrets should not be committed into the repository. If we see such a thing during a review we will request for changes.
The following example fictiously adds authenticaton to the previously used
pokemon API. To enable use of secrets, You will need to map the necessary
secrets as arguments into the source by using the secret_ref_arg. This special
function is used by OSO's dagster's infrastructure to resolve secrets properly
from the currently configured oso_dagster.utils.SecretResolver. It takes two
arguments group_name and key. These are used to find a secret.
from request.auth import HTTPBasicAuth
import dlt
from dlt.sources.helpers.rest_client import RESTClient
from dlt.sources.helpers.rest_client.paginators import JSONResponsePaginator
from pydantic import BaseModel
from oso_dagster.factories import dlt_factory, pydantic_to_dlt_nullable_columns
class Pokemon(BaseModel):
name: str
url: str
@dlt.resource(
name="pokemon",
columns=pydantic_to_dlt_nullable_columns(Pokemon),
)
def get_pokemons(poke_client: RESTClient): # (1)
for page in poke_client.paginate(
"/pokemon",
params={
"limit": 100,
},
):
for pokemon in page.results:
yield pokemon
@dlt_factory()
def pokemon(
poke_user: str = secret_ref_arg(group_name="pokemon", key="username"),
poke_pass: str = secret_ref_arg(group_name="pokemon", key="password")
):
auth = HTTPBasicAuth(poke_user, poke_pass) # (2)
client = RESTClient(
base_url="https://pokeapi.co/api/v2",
paginator=JSONResponsePaginator(next_url_path="next"),
data_selector="results",
auth=auth,
)
yield get_pokemons(client) # (3)
There are a few critical changes we've made in this example:
- You will notice that the RESTClient is no longer a global variable in the module. The dlt resource here now requires it as an argument. This will allow us to ensure we configure the authentication for this client properly
- Starting on this line and the immediately following line, the authentication
of for the
RESTClientis configured. The details may differ if you're not using a RESTClient instance but this provides an example for how to pass in the required secrets to instantiate the necessary client. - The dlt resource is yielded as usual but it is instead passed the
RESTClientinstance that has been configured with authentication credentials.
Add the asset to the OSO Dagster configuration
Submit a pull request
When you are ready to deploy, submit a pull request of your changes to OSO. OSO maintainers will work with you to get the code in shape for merging. For more details on contributing to OSO, check out CONTRIBUTING.md.
Verify deployment
Our Dagster deployment should automatically recognize the asset after merging your pull request to the main branch. You should be able to find your new asset in the global asset list.
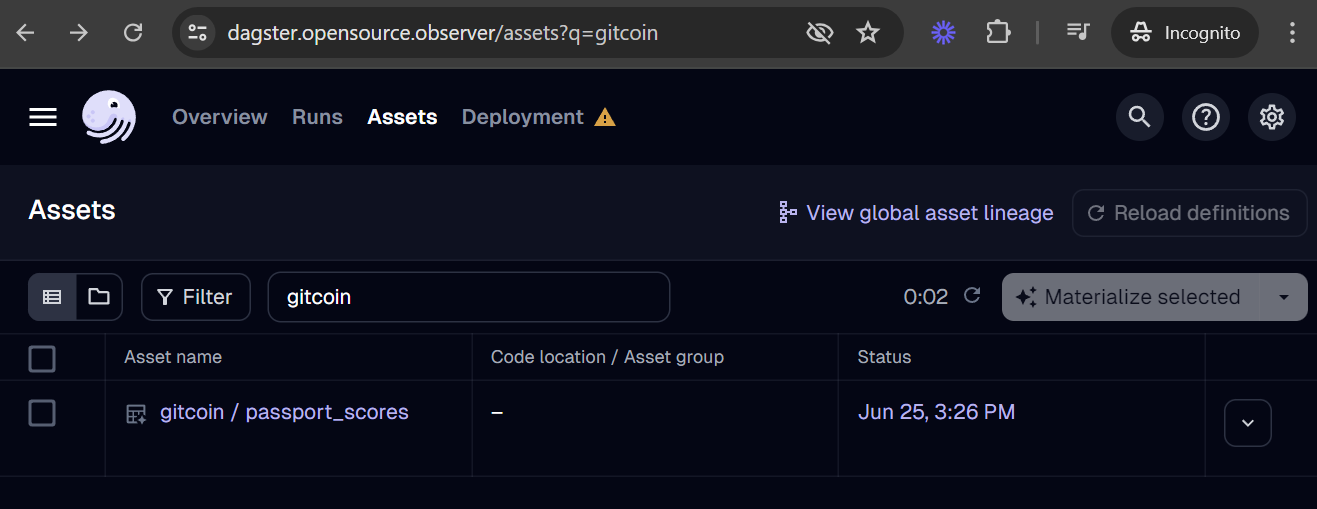
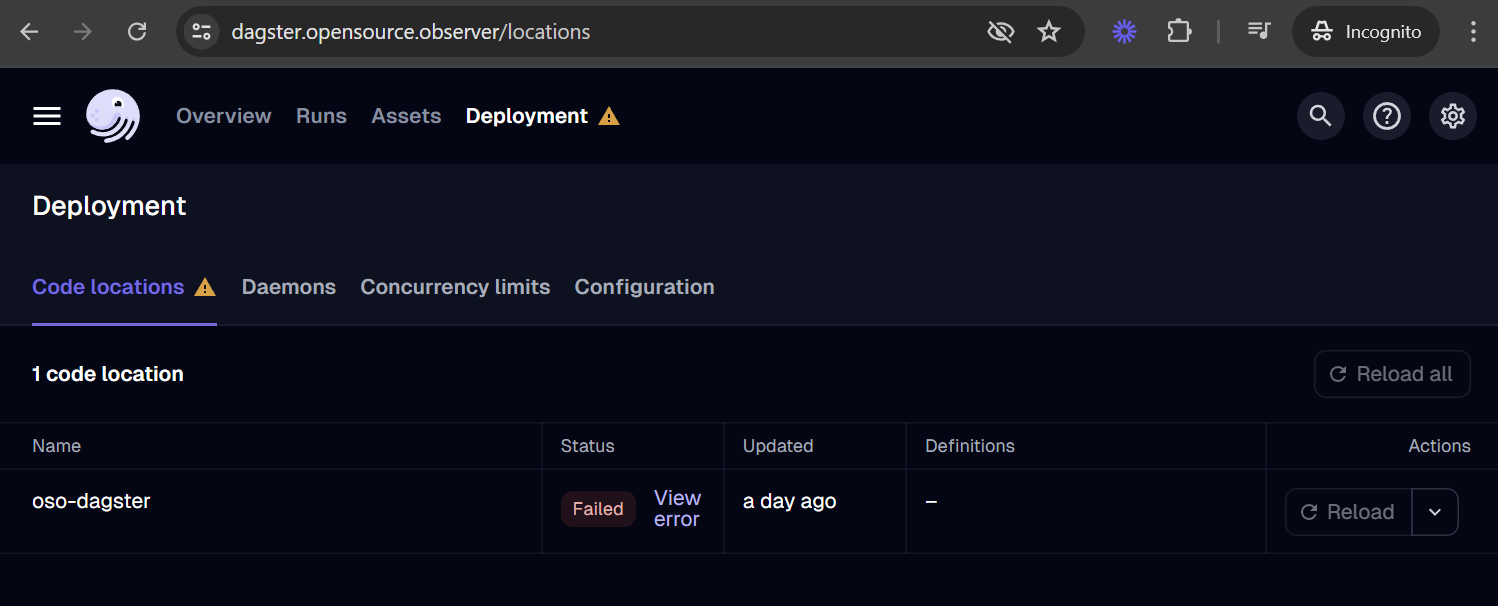
If your asset is missing, you can check for loading errors and the date of last code load in the Deployment tab. For example, if your code has a bug and leads to a loading error, it may look like this:
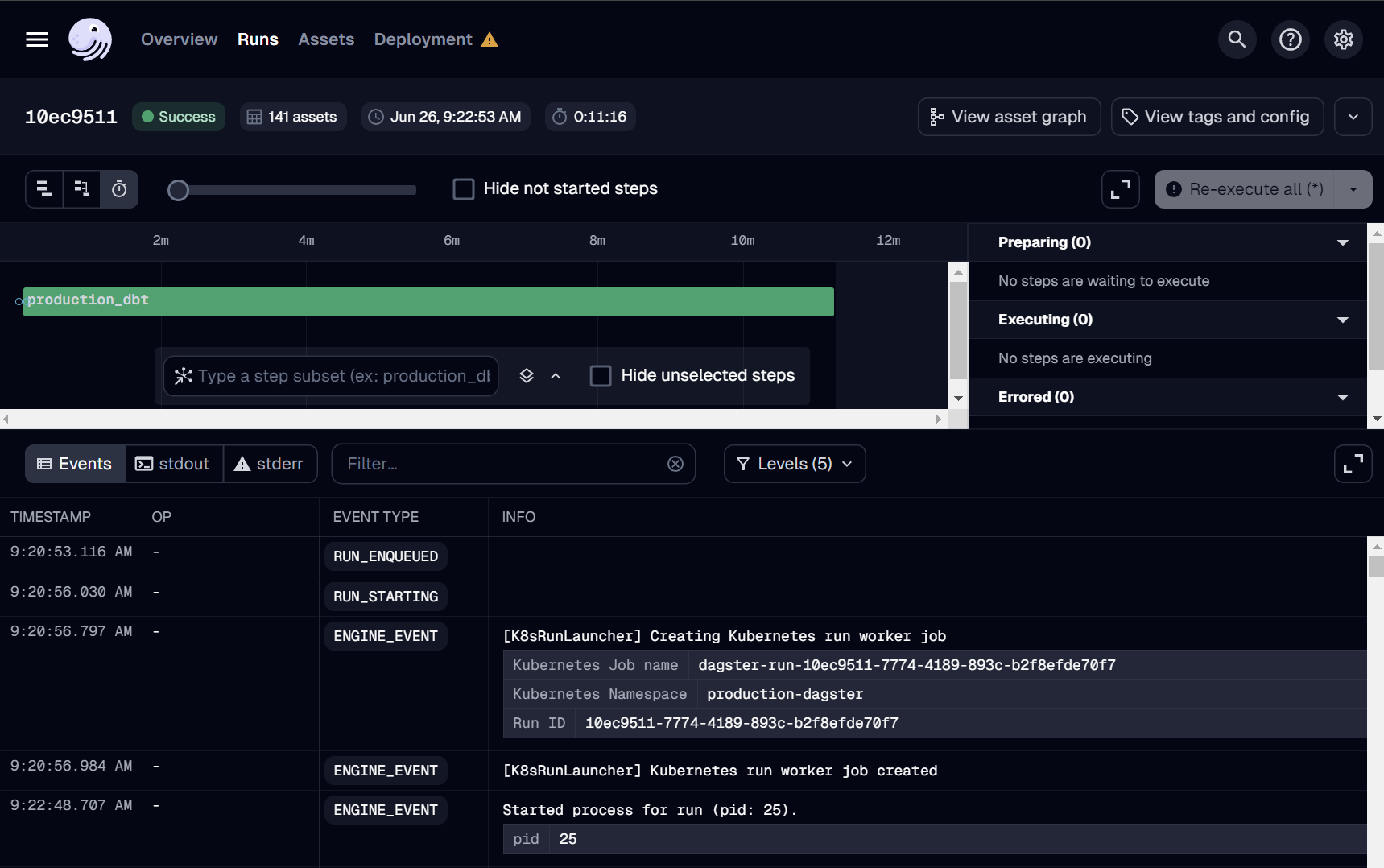
Run it!
If this is your first time adding an asset, we suggest reaching out to the OSO team over Discord to run deploys manually. You can monitor all Dagster runs here.
Dagster also provides automation to run jobs on a schedule (e.g. daily), after detecting a condition using a Python-defined sensor (e.g. when a file appears in GCS), and using auto-materialization policies.
We welcome any automation that can reduce the operational burden in our continuous deployment. However, before merging any job automation, please reach out to the OSO devops team on Discord with an estimate of costs, especially if it involves large BigQuery scans. We will reject or disable any jobs that lead to increased infrastructure instability or unexpected costs.
Defining a dbt source
In order to make the new dataset available to the data pipeline,
you need to add it as a dbt source.
In this example, we create a source in oso/warehouse/dbt/models/
(see source)
for the Ethereum mainnet
public dataset.
sources:
- name: ethereum
database: bigquery-public-data
schema: crypto_ethereum
tables:
- name: transactions
identifier: transactions
- name: traces
identifier: traces
We can then reference these tables in downstream models with
the source macro:
select
block_timestamp,
`hash` as transaction_hash,
from_address,
receipt_contract_address
from {{ source("ethereum", "transactions") }}
Next steps
- SQL Query Guide: run queries against the data you just loaded
- Connect OSO to 3rd Party tools: explore your data using tools like Hex.tech, Tableau, and Metabase
- Write a dbt model: contribute new impact and data models to our data pipeline