Writing Custom Dagster Assets
Before writing a fully custom Dagster asset, we recommend you first see if the previous guides on BigQuery datasets, database replication, API crawling may be a better fit. This guide should only be used in the rare cases where you cannot use the other methods.
Write your Dagster asset
Dagster provides a great tutorial on writing Dagster assets that write to BigQuery.
At a high-level, there are 2 possible pathways:
-
Option 1: Using the BigQuery resource
By using the BigQuery resource directly, you'll execute SQL queries directly on BigQuery to create and interact with tables. This is ideal for large datasets where you do not want the Dagster process to be in the critical path of dataflow. Rather, Dagster orchestrates jobs remotely out-of-band. -
Option 2: BigQuery I/O Manager
This method offers significantly more control, by loading data into a DataFrame on the Dagster process for arbitrary computation. However because Dagster is now on the critical path computing on data, it can lead to performance issues, especially if the data does not easily fit in memory.
Assets should be added to warehouse/oso_dagster/assets/. All assets defined in
this package are automatically loaded into Dagster from the main branch of the
git repository.
For an example of a custom Dagster asset, check out the
asset for oss-directory,
where we use the oss-directory Python package
to fetch data from the
oss-directory repo
and load it into BigQuery using the I/O manager approach.
Creating an asset factory (optional)
If your asset represents a common pattern, we encourage that you turn this into a factory. For example, our tutorial on Google Cloud Storage-based assets is an example of a factory pattern.
We suggest creating a vanilla asset and see it work in production before abstracting it out into a factory
In order to create a factory, add it to the
warehouse/oso_dagster/factories/ directory.
The factory needs to return a AssetFactoryResponse
that represents the different aspects of an asset,
including sensors, jobs, and checks.
# warehouse/oso_dagster/factories/common.py
@dataclass
class AssetFactoryResponse:
assets: List[AssetsDefinition]
sensors: List[SensorDefinition] = field(default_factory=lambda: [])
jobs: List[JobDefinition] = field(default_factory=lambda: [])
checks: List[AssetChecksDefinition] = field(default_factory=lambda: [])
For example, below we share the method signature of the GCS factory:
# warehouse/oso_dagster/factories/gcs.py
## Factory configuration
@dataclass(kw_only=True)
class IntervalGCSAsset(BaseGCSAsset):
interval: Interval
mode: SourceMode
retention_days: int
## Factory function
def interval_gcs_import_asset(config: IntervalGCSAsset):
# Asset definition
@asset(name=config.name, key_prefix=config.key_prefix, **config.asset_kwargs)
def gcs_asset(
context: AssetExecutionContext, bigquery: BigQueryResource, gcs: GCSResource
) -> MaterializeResult:
# Load GCS files into BigQuery
...
# Asset sensor definition
@asset_sensor(
asset_key=gcs_asset.key,
name=f"{config.name}_clean_up_sensor",
job=gcs_clean_up_job,
default_status=DefaultSensorStatus.STOPPED,
)
def gcs_clean_up_sensor(
context: SensorEvaluationContext, gcs: GCSResource, asset_event: EventLogEntry
):
# Detect when we can cleanup old data files on GCS
...
# Asset cleanup job
@job(name=f"{config.name}_clean_up_job")
def gcs_clean_up_job():
# Delete old files on GCS
...
# Return an instance
return AssetFactoryResponse([gcs_asset], [gcs_clean_up_sensor], [gcs_clean_up_job])
Then you can instantiate the asset with the factory
in warehouse/oso_dagster/assets/.
For example, we get periodic Parquet file dumps
from Gitcoin Passport into the GCS bucket named
oso-dataset-transfer-bucket.
Using the GCS factory,
we load the data into the BigQuery table named
gitcoin.passport_scores.
# warehouse/oso_dagster/assets/gitcoin.py
gitcoin_passport_scores = interval_gcs_import_asset(
IntervalGCSAsset(
key_prefix="gitcoin",
name="passport_scores",
project_id="opensource-observer",
bucket_name="oso-dataset-transfer-bucket",
path_base="passport",
file_match=r"(?P<interval_timestamp>\d\d\d\d-\d\d-\d\d)/scores.parquet",
destination_table="passport_scores",
raw_dataset_name="oso_raw_sources",
clean_dataset_name="gitcoin",
interval=Interval.Daily,
mode=SourceMode.Overwrite,
retention_days=10,
format="PARQUET",
),
)
Add the asset to the OSO Dagster configuration
Submit a pull request
When you are ready to deploy, submit a pull request of your changes to OSO. OSO maintainers will work with you to get the code in shape for merging. For more details on contributing to OSO, check out CONTRIBUTING.md.
Verify deployment
Our Dagster deployment should automatically recognize the asset after merging your pull request to the main branch. You should be able to find your new asset in the global asset list.
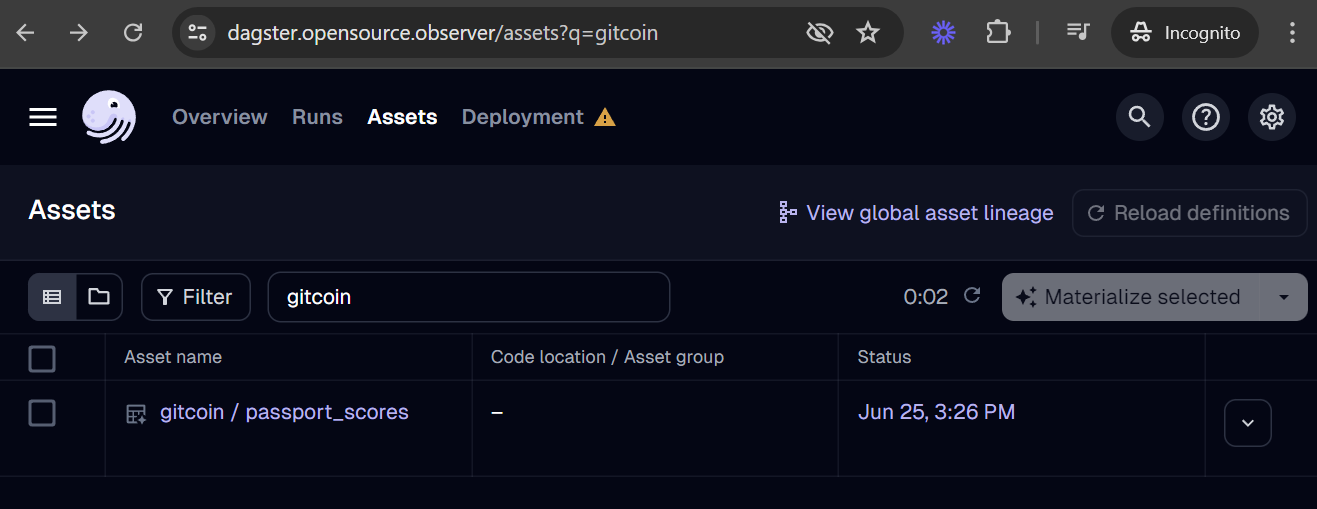
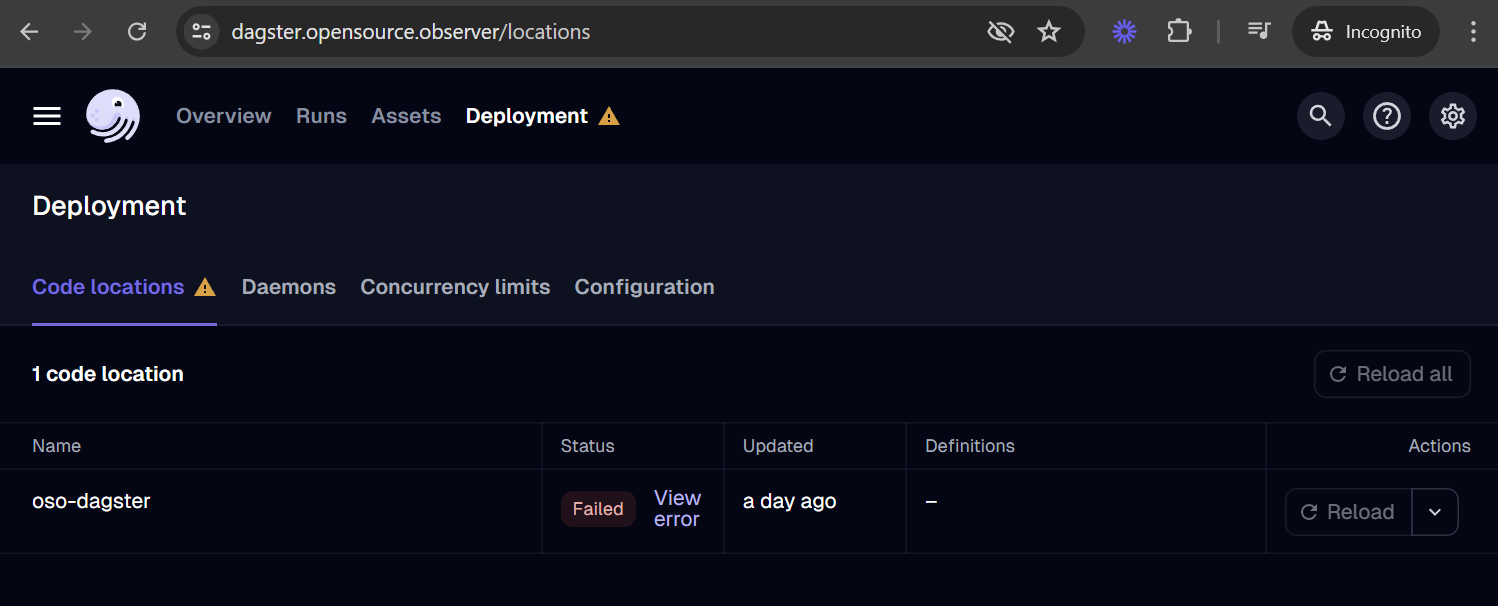
If your asset is missing, you can check for loading errors and the date of last code load in the Deployment tab. For example, if your code has a bug and leads to a loading error, it may look like this:
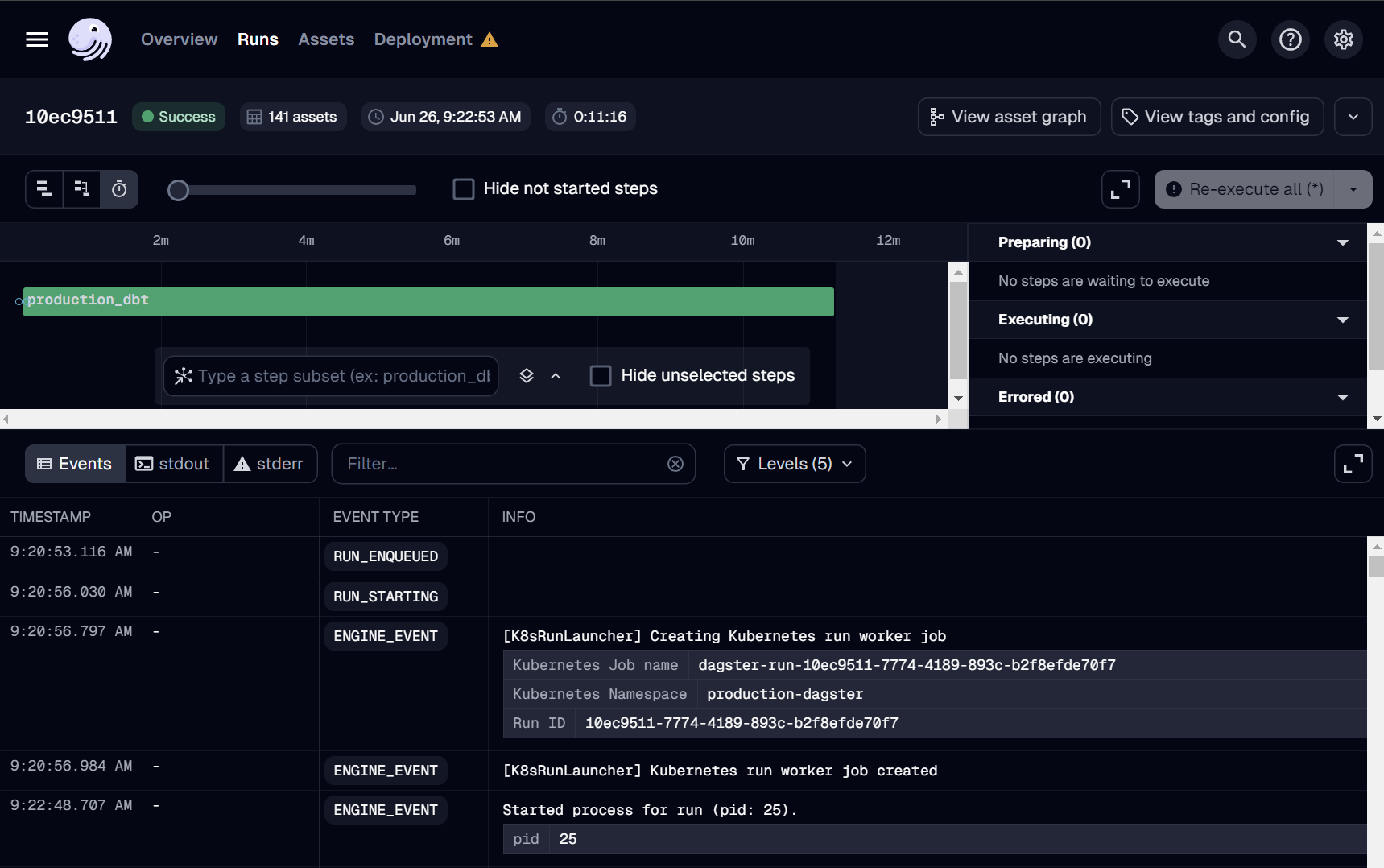
Run it!
If this is your first time adding an asset, we suggest reaching out to the OSO team over Discord to run deploys manually. You can monitor all Dagster runs here.
Dagster also provides automation to run jobs on a schedule (e.g. daily), after detecting a condition using a Python-defined sensor (e.g. when a file appears in GCS), and using auto-materialization policies.
We welcome any automation that can reduce the operational burden in our continuous deployment. However, before merging any job automation, please reach out to the OSO devops team on Discord with an estimate of costs, especially if it involves large BigQuery scans. We will reject or disable any jobs that lead to increased infrastructure instability or unexpected costs.
Defining a dbt source
In order to make the new dataset available to the data pipeline,
you need to add it as a dbt source.
In this example, we create a source in oso/warehouse/dbt/models/
(see source)
for the Ethereum mainnet
public dataset.
sources:
- name: ethereum
database: bigquery-public-data
schema: crypto_ethereum
tables:
- name: transactions
identifier: transactions
- name: traces
identifier: traces
We can then reference these tables in downstream models with
the source macro:
select
block_timestamp,
`hash` as transaction_hash,
from_address,
receipt_contract_address
from {{ source("ethereum", "transactions") }}
Next steps
- SQL Query Guide: run queries against the data you just loaded
- Connect OSO to 3rd Party tools: explore your data using tools like Hex.tech, Tableau, and Metabase
- Write a dbt model: contribute new impact and data models to our data pipeline