Connect via BigQuery
BigQuery's built-in data-sharing capabilities make it trivially easy to integrate any public dataset into the OSO data pipeline, provided the dataset exists in the US multi-region.
If the dataset needs to be replicated, see our guide on BigQuery Data Transfer Service.
Make the data available in the US region
In order for our data pipeline to operate on the data, it must be in the US multi-region.
If you have reason to keep the dataset in a different region, you can use the BigQuery Data Transfer Service to easily copy the dataset to the US region. To manually define this as a transfer job in your own Google project, you can do this directly from the BigQuery Studio.
OSO will also copy certain valuable datasets into the
opensource-observer project via the BigQuery Data Transfer Service
See the guide on BigQuery Data Transfer Service
add dataset replication as a Dagster asset to OSO.
Make the data accessible to our Google service account
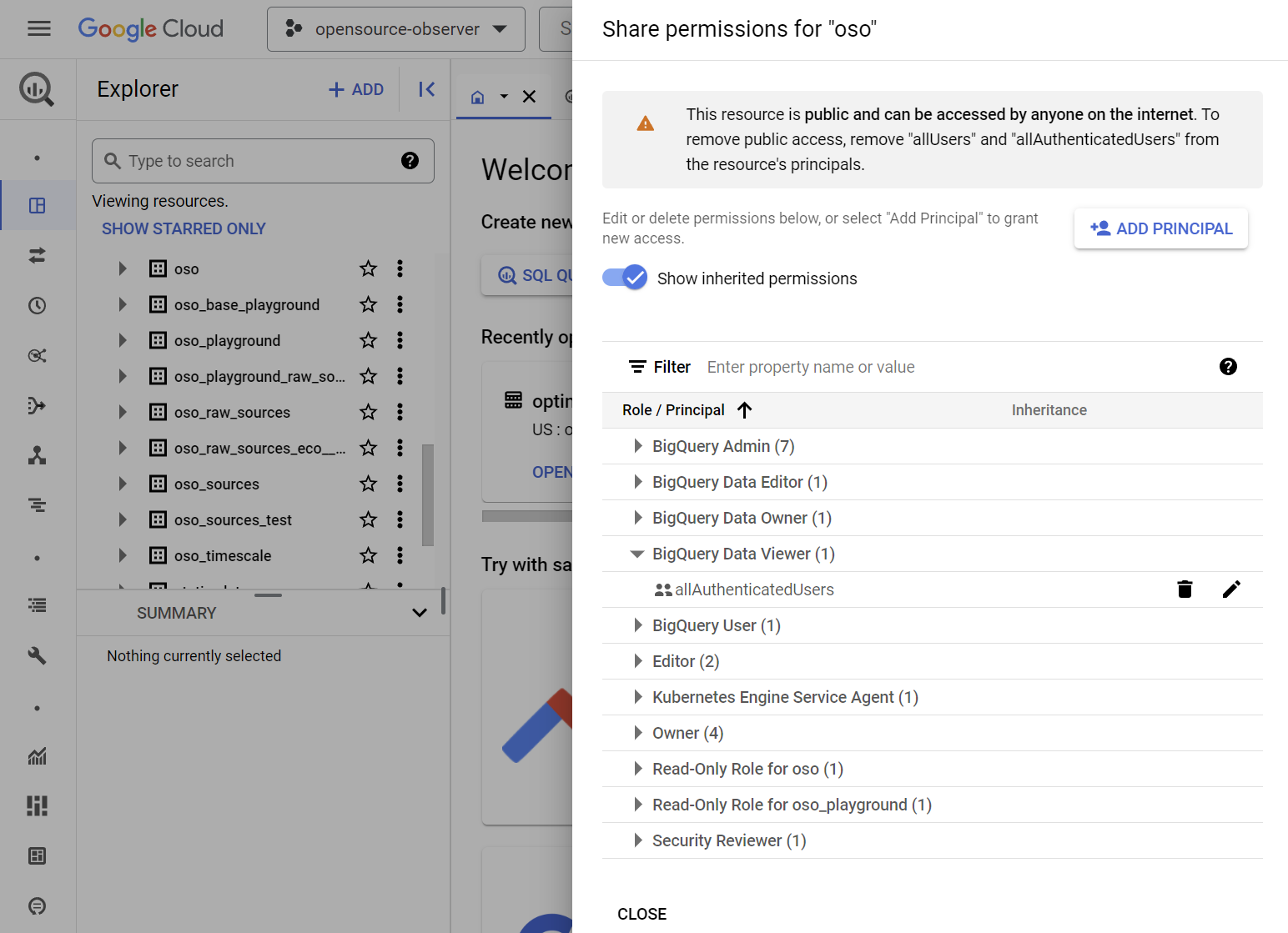
The easiest way to do this is to make the BigQuery dataset publicly accessible.
Add the allAuthenticatedUsers as the "BigQuery Data Viewer"
If you have reasons to keep your dataset private, you can reach out to us directly on our Discord.
Defining a dbt source
For example, Google maintains a public dataset for Ethereum mainnet.
As long as the dataset is publicly available in the US region,
we can create a dbt source in oso/warehouse/dbt/models/
(see source):
sources:
- name: ethereum
database: bigquery-public-data
schema: crypto_ethereum
tables:
- name: transactions
identifier: transactions
- name: traces
identifier: traces
We can then reference these tables in a downstream model with
the source macro:
select
block_timestamp,
`hash` as transaction_hash,
from_address,
receipt_contract_address
from {{ source("ethereum", "transactions") }}
Creating a playground dataset (optional)
If the source table is large, we will want to extract a subset of the data into a playground dataset for testing and development.
For example for GitHub event data,
we copy just the last 14 days of data
into a playground dataset, which is used
when the dbt target is set to playground
(see source):
sources:
- name: github_archive
database: |
{%- if target.name in ['playground', 'dev'] -%} opensource-observer
{%- elif target.name == 'production' -%} githubarchive
{%- else -%} invalid_database
{%- endif -%}
schema: |
{%- if target.name in ['playground', 'dev'] -%} oso
{%- elif target.name == 'production' -%} day
{%- else -%} invalid_schema
{%- endif -%}
tables:
- name: events
identifier: |
{%- if target.name in ['playground', 'dev'] -%} stg_github__events
{%- elif target.name == 'production' -%} 20*
{%- else -%} invalid_table
{%- endif -%}
Choosing a playground window size
There is a fine balance between choosing a playground data set window that is sufficiently small for affordable testing and development, yet produces meaningful results to detect issues in your queries.
Coming soon... This section is a work in progress.
Copying the playground dataset
Coming soon... This section is a work in progress.