Data Overview
First, you need to set up your BigQuery account. You can do this by going to the Get Started page.
OSO Data Exchange on Analytics Hub
To explore all the OSO datasets available, check out our BigQuery data exchange.
OSO Production Data Pipeline

Every stage of the OSO data pipeline is queryable and downloadable. Like most dbt-based pipelines, we split the pipeline stages into staging, intermediate, and mart models.
You can find the reference documentation on every data model on https://models.opensource.observer/
OSO Mart Models
These are the final product from the data pipeline, which is served from our API.
For example, you can get a list of oss-directory projects
select
project_id,
project_name,
display_name,
description
from `YOUR_PROJECT_NAME.oso_production.projects_v1` LIMIT 10
select *
from `YOUR_PROJECT_NAME.oso_production.code_metrics_by_project_v1`
where project_name = 'uniswap'
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Note: Unless the model name is versioned, expect that the model is unstable and should not be depended on in a live production application.
OSO Staging / Intermediate Models
From source data, we produce a "universal event table", currently stored at
int_events.
Each event consists of an event_type
(e.g. a git commit or contract invocation),
to/from artifacts,
a timestamp, and an amount.
From this event table, we aggregate events in downstream models to produce our metrics.
For example, you may find it cheaper to run queries against
int_events_daily_to_project.
SELECT event_source, SUM(amount)
FROM `YOUR_PROJECT_NAME.oso_production.int_events_daily_to_project`
WHERE project_id = 'XSDgPwFuQVcj57ARcKTGrm2w80KKlqJxaBWF6jZqe7w=' AND event_type = 'CONTRACT_INVOCATION_DAILY_COUNT'
GROUP BY project_id, event_source
OSO Playground
We maintain a subset of projects and events in a playground dataset for testing and development. All of the production models are mirrored in this environment.
Source Data
GitHub Data

- Reference documentation
- Code License: MIT.
- Data governed by the GitHub terms of service.
- Updated hourly
GitHub data is predominantly provided by the incredible GH Archive project, which publishes a public archive of historical events to GitHub.
For example, to count the number of issues opened, closed, and reopened on 2020/01/01:
SELECT event as issue_status, COUNT(*) as cnt FROM (
SELECT type, repo.name, actor.login,
JSON_EXTRACT(payload, '$.action') as event,
FROM `githubarchive.day.20200101`
WHERE type = 'IssuesEvent'
)
GROUP by issue_status;
Open Source Insights

- Reference documentation
- Data License: CC-BY 4.0
Open Source Insights (aka deps.dev) is a service developed and hosted by Google to help developers better understand the structure, construction, and security of open source software packages. The service examines each package, constructs a full, detailed graph of its dependencies and their properties, and makes the results available to anyone who could benefit from them. The goal is to provide developers with a picture of how their software is put together, how that changes as dependencies change, and what the consequences might be.
For example, to determine which packages have the most dependents:
DECLARE
Sys STRING DEFAULT 'CARGO';
SELECT
Name,
Version,
FROM (
SELECT
Name,
Version,
ROW_NUMBER()
OVER (PARTITION BY
Name
ORDER BY
VersionInfo.Ordinal DESC) AS RowNumber
FROM
`bigquery-public-data.deps_dev_v1.PackageVersionsLatest`
WHERE
System = Sys
AND VersionInfo.IsRelease)
WHERE RowNumber = 1;
Ethereum Data

- Reference documentation
- Code License: MIT.
The Google Cloud team maintains a public Ethereum dataset. This is backed by the ethereum-etl project.
For example, to get 10 transactions from the latest block
select
`hash`,
block_number,
from_address,
to_address,
value,
gas,
gas_price
from `bigquery-public-data.crypto_ethereum.transactions` as transactions
order by block_number desc
limit 10
Optimism Data
- Code License: Apache-2.0
- Data governed by the OSO terms of service
OSO is proud to provide public datasets for the Superchain, backed by our partners at Goldsky.
We currently provide blocks, transactions, and traces for the following networks:
- Optimism mainnet (Reference docs , Updated daily)
- Base (Reference docs , Updated daily)
- Frax (Reference docs , Updated daily)
- Metal (Reference docs , Updated daily)
- Mode (Reference docs , Updated daily)
- PGN (Reference docs , Updated daily)
- Zora (Reference docs , Updated daily)
For example, to get deployed contracts from a particular address on the Base network:
select
traces.block_timestamp,
traces.transaction_hash,
txs.from_address as originating_address,
txs.to_address as originating_contract,
traces.from_address as factory_address,
traces.to_address as contract_address
from `YOUR_PROJECT_NAME.superchain.base_traces` as traces
inner join transactions as txs
on txs.hash = traces.transaction_hash
where
LOWER(traces.from_address) != "0x3fab184622dc19b6109349b94811493bf2a45362"
and LOWER(trace_type) in ("create", "create2")
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Arbitrum Data

Arbitrum is a Layer 2 scaling solution for Ethereum. We currently provide blocks, transactions, and traces for Arbitrum's flagship network, Arbitrum One.
For example, to get the average gas per transaction for each block on Arbitrum One on September 1st, 2024:
select
number,
gas_used / transaction_count as gas_per_txn
from `YOUR_PROJECT_NAME.arbitrum_one.arbitrum_blocks`
where timestamp between '2024-09-01' and '2024-09-02'
order by number
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Filecoin Data

Filecoin is a decentralized storage network designed to store humanity's most important information. This dataset mirrors the dataset offered by Lily for use in the OSO data pipeline. It includes storage deals, miners, FVM transactions, and much more.
For example, this is how to get how many messages were sent to the network in the last month:
select
count(cid) as total_messages
from `YOUR_PROJECT_NAME.filecoin_lily.parsed_messages`
where
cast(timestamp_seconds((height * 30) + 1598306400) as date) > current_date() - interval 1 month
Farcaster Data

Farcaster is a decentralized social network built on Ethereum. This dataset mirrors the dataset offered by Indexing for use in the OSO data pipeline. It includes casts, links, reactions, verifications, and profiles.
For example, to get the users with the most lifetime reactions:
SELECT
r.target_cast_fid as fid,
json_value(p.data, "$.display") as display_name,
COUNT(*) as reaction_count
FROM `YOUR_PROJECT_NAME.farcaster.reactions` as r
LEFT JOIN `YOUR_PROJECT_NAME.farcaster.profiles` as p ON r.target_cast_fid = p.fid
GROUP BY fid, display_name
ORDER BY reaction_count DESC
Here's another use case, showing how to derive all the verified Ethereum addresses owned by a Farcaster user:
WITH
profiles AS (
SELECT
v.fid,
v.address,
p.custody_address,
JSON_VALUE(p.data, "$.username") AS username,
FROM `YOUR_PROJECT_NAME.farcaster.verifications` v
JOIN `YOUR_PROJECT_NAME.farcaster.profiles` p ON v.fid = p.fid
WHERE v.deleted_at IS NULL
),
eth_addresses AS (
SELECT
fid,
username,
address
FROM profiles
WHERE LENGTH(address) = 42
UNION ALL
SELECT
fid,
username,
custody_address AS address
FROM profiles
)
SELECT DISTINCT
fid,
username,
address
FROM eth_addresses
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Lens Data

Lens Protocol is an open social network. This dataset mirrors the dataset offered by Lens for use in the OSO data pipeline. It includes data from the Polygon network.
Gitcoin and Passport Data

Gitcoin is the hub of grantmaking in the Ethereum ecosystem. All project, round, and donation data from regendata.xyz is available in this dataset and updated daily.
For example, you can get the total amount of donations mapped to projects in OSO:
with project_mapping as (
select distinct
gitcoin_lookup.project_id as gitcoin_id,
oso_projects.project_name as oso_name,
oso_projects.display_name as display_name
from `YOUR_PROJECT_NAME.gitcoin.project_groups_summary` as gitcoin_groups
left join `YOUR_PROJECT_NAME.gitcoin.project_lookup` as gitcoin_lookup
on gitcoin_groups.group_id = gitcoin_lookup.group_id
join `YOUR_PROJECT_NAME.oso_production.int_artifacts_in_ossd_by_project` as oso_artifacts
on gitcoin_groups.latest_project_github = oso_artifacts.artifact_namespace
join `YOUR_PROJECT_NAME.oso_production.projects_v1` as oso_projects
on oso_artifacts.project_id = oso_projects.project_id
)
select
donations.timestamp,
donations.donor_address,
project_mapping.oso_name,
project_mapping.display_name,
donations.amount_in_usd
from `YOUR_PROJECT_NAME.gitcoin.all_donations` as donations
join project_mapping
on donations.project_id = project_mapping.gitcoin_id
Passport is a web3 identity verification protocol. OSO and Gitcoin have collaborated to make this dataset of address scores available for use in understanding user reputations.
For example, you can can vitalik.eth's passport score:
select
passport_address,
last_score_timestamp,
evidence_rawScore,
evidence_threshold,
from YOUR_PROJECT_NAME.gitcoin.passport_scores
where passport_address = '0xd8da6bf26964af9d7eed9e03e53415d37aa96045'
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
OpenRank Data

OpenRank is a reputation protocol that enables verifiable compute for a large class of reputation algorithms, in particular those that (a) operate on a graph, (b) are iterative in nature and (c) have a tendency toward convergence. Such algorithms include EigenTrust, Collaborative Filtering, Hubs and Authorities, Latent Semantic Analysis, etc.
In this dataset, Farcaster users reputations are scored in 2 ways:
- With
globaltrust, we calculate global reputation scores, seeded by the trust of Optimism badgeholders. - With
localtrust, you can get reputation scores of other users relative to specified user.
For example, you can get the globaltrust reputation score of vitalik.eth
select
strategy_id,
i,
v,
date
from YOUR_PROJECT_NAME.karma3.globaltrust
where i = 5650
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Ethereum Attestation Service

Ethereum Attestation Service (EAS) is an infrastructure public good for making attestations onchain or offchain about anything.
This dataset mirrors the dataset offered by EAS for use in the OSO data pipeline, currenty showing all attestations on the Optimism network.
For example, you can get a list of all * official * RetroPGF badgeholders:
select
recipient as badgeholder,
json_value(decoded_data_json, "$[0].value.value") as rpgfRound
from YOUR_PROJECT_NAME.ethereum_attestation_service_optimism.attestations
where
revoked = False
and schema_id = '0xfdcfdad2dbe7489e0ce56b260348b7f14e8365a8a325aef9834818c00d46b31b'
and attester = '0x621477dBA416E12df7FF0d48E14c4D20DC85D7D9'
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Open Collective Data

Open Collective is a platform for transparent finances and governance for open source projects.
The Open Collective datasets contains all transactions realized on the platform since its inception. Separate datasets are available for expenses and deposits.
For example, you can get the total amount of donations in USD made to the pandas project:
select
SUM(CAST(JSON_VALUE(amount, "$.value") as FLOAT64)) as total_amount,
from
YOUR_PROJECT_NAME.open_collective.deposits
where
JSON_VALUE(amount, "$.currency") = "USD"
and JSON_VALUE(to_account, "$.id") = "ov349mrw-gz75lpy9-975qa08d-jeybknox"
Remember to replace 'YOUR_PROJECT_NAME' with the name of your project in the query.
Subscribe to a dataset
1. Data exchange listings
For datasets listed on the OSO public data exchange, click on the "Subscribe on BigQuery" button to create a new dataset that is linked to OSO.
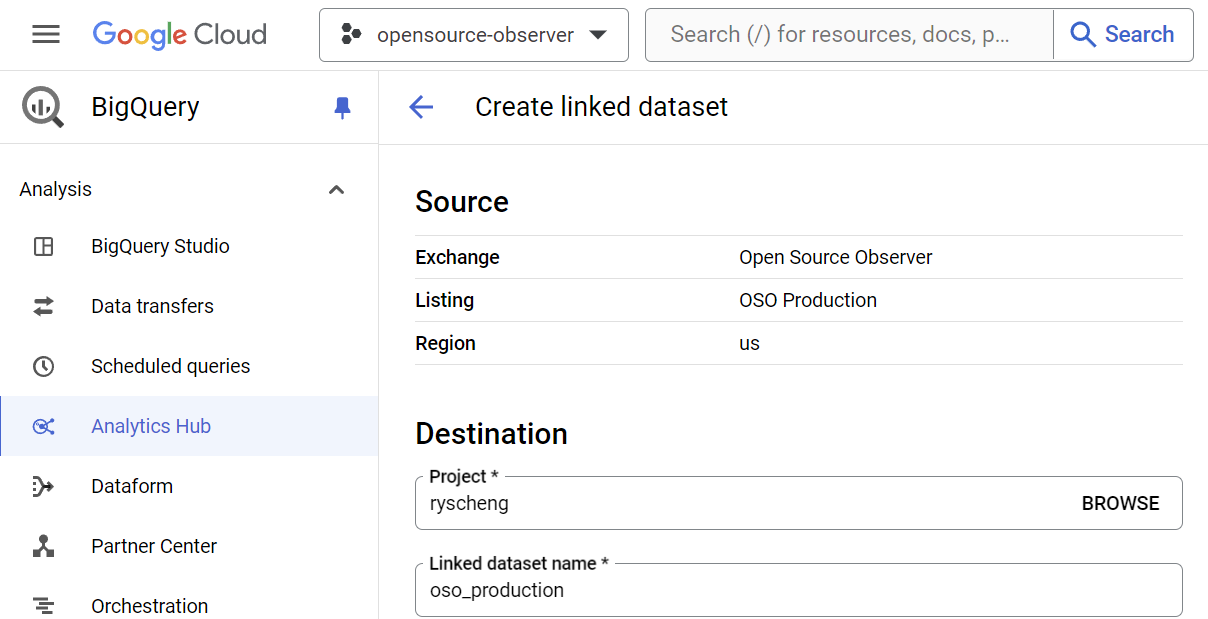
This has a few benefits:
- Data is automatically kept live and real-time with OSO
- You keep a reference to the data in your own GCP project
- This gives OSO the ability to track public usage of models
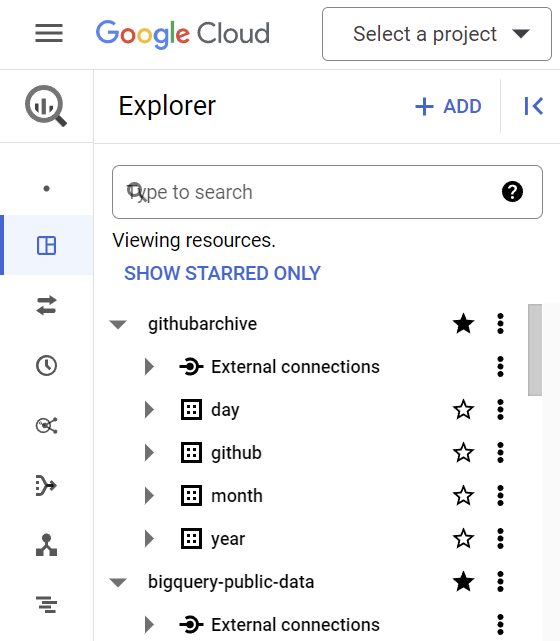
2. Direct access to datasets
For datasets without a listing on the OSO public data exchange, we make the dataset open to public queries for direct queries. Click on the "View on BigQuery" button to go straight to the dataset.
You can star the dataset to keep it in your project.
Next steps
Once you've subscribed our datasets to your own Google project, you can start to run queries and analyses with a variety of tools.
Here are a few to start:
- SQL Query Guide: to quickly query and download any data
- Python notebooks: to do more in-depth data science and processing
- Connect OSO to 3rd Party tools: like Hex.tech, Tableau, and Metabase