Technical Architecture
OSO's goal is to make it simple to contribute by providing an automatically deployed data pipeline so that the community can build this open data warehouse together. All of the code for this architecture is available to view/copy/redeploy from the OSO Monorepo.
Pipeline Overview
OSO maintains an ETL data pipeline that is continuously deployed from our monorepo and regularly indexes all available event data about projects in the oss-directory.
- Extract: raw event data from a variety of public data sources (e.g., GitHub, blockchains, npm, Open Collective)
- Transform: the raw data into impact metrics and impact vectors per project (e.g., # of active developers)
- Load: the results into various OSO data products (e.g., our API, website, widgets)
The following diagram illustrates Open Source Observer's technical architecture.
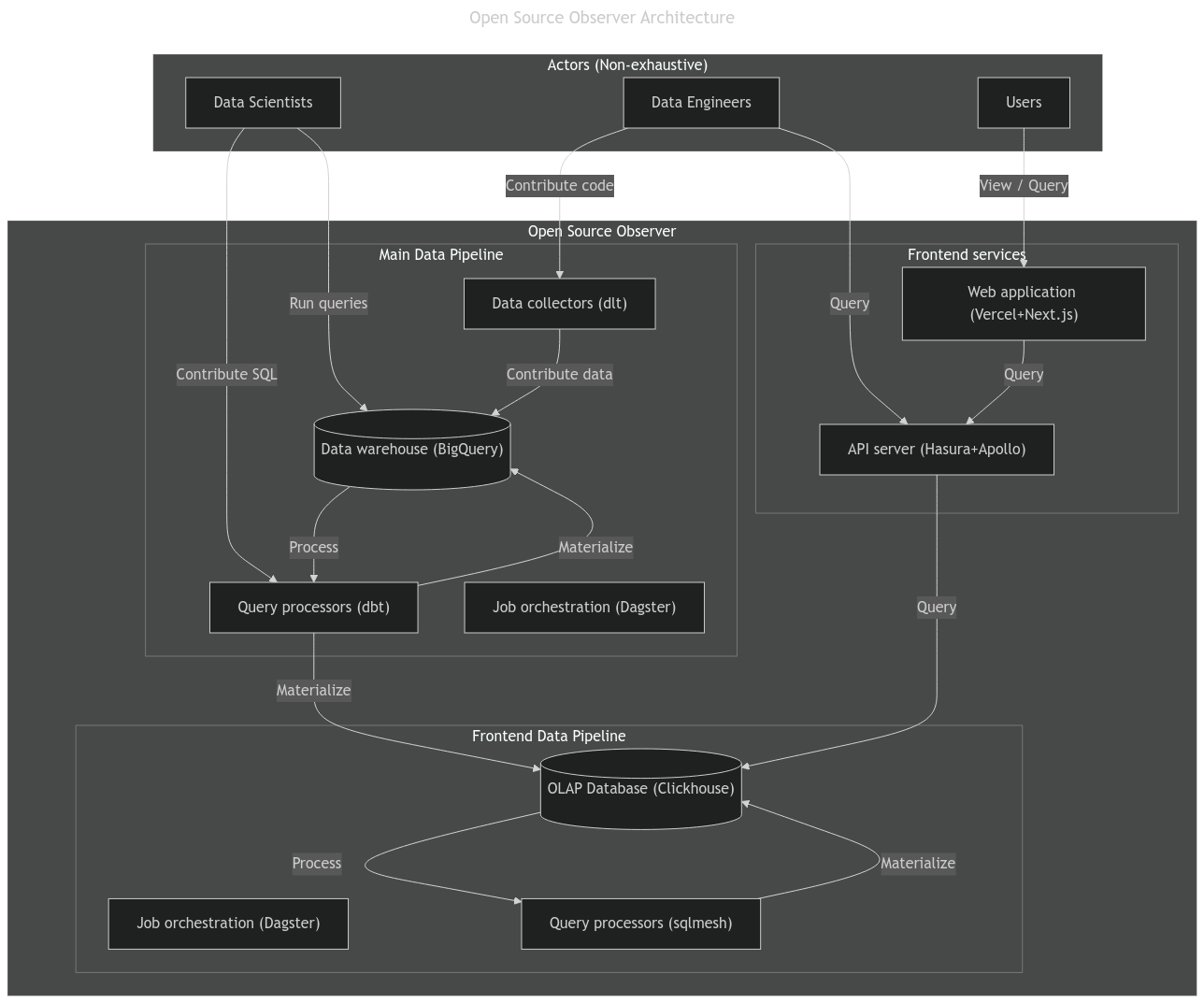
Major Components
The architecture has the following major components.
Data Orchestration
Dagster is the central data orchestration system, which manages the entire pipeline, from the data ingestion (e.g. via dlt connectors), the dbt pipeline, the sqlmesh pipeline, to copying mart models to data serving infrastructure.
You can see our public Dagster dashboard at https://dagster.opensource.observer/.
Data Warehouse
Currently all data is stored and processed in Google BigQuery. All of the collected data or aggregated views used by OSO is also made publicly available here (if it is not already a public dataset on BigQuery). Anyone with can view, query, or build off of any stage in the pipeline. In the future we plan to explore a decentralized lakehouse.
To see all datasets that you can subscribe to, check out our Data Overview.
dbt pipeline
We use a dbt pipeline to clean and normalize the data into a universal event table. You can read more about our event model here.
OLAP database
We use Clickhouse as a frontend database for serving live queries to the API server and frontend website, as well as running a sqlmesh data pipeline.
sqlmesh pipeline
A sqlmesh pipeline is used for computing time series metrics from the universal event table, which is copied from the BigQuery dbt pipeline.
API service
We use Hasura to automatically generate a GraphQL API from our Clickhouse database. We then use an Apollo Router to service user queries to the public. The API can be used by external developers to integrate insights from OSO. Rate limits or cost sharing subscriptions may apply to it's usage depending on the systems used. This also powers the OSO website.
OSO Website
The OSO website is served at https://www.opensource.observer. This website provides an easy to use public view into the data. We currently use Next.js hosted by Vercel.
Open Architecture for Open Source Data
The architecture is designed to be fully open to maximum open source collaboration. With contributions and guidance from the community, we want Open Source Observer to evolve as we better understand what impact looks like in different domains.
All code is open source in our monorepo. All data, including every stage in our pipeline, is publicly available on BigQuery. All data orchestration is visible in our public Dagster dashboard.
You can read more about our open philosophy on our blog.