Time Series Metrics Factory Deep Dive
This guide is for an in-depth understanding of our model generation factory that is used to generate the time series metrics for OSO. If you'd like a more practical example of how to add new time series metrics models, go here.
Background
The creation of the time series metrics factory requires some deeper knowledge about sqlmesh and sqlglot. Much of this information is available in the documentation for sqlmesh and sqlglot but the combined utility is not readily documented. This section covers an overview of prerequisite knowledge:
SQLMesh Python Models
The timeseries metrics generation take advantage of the fact that sqlmesh allows for python models as well as sql models. A python model in sqlmesh looks something like this:
import typing as t
from datetime import datetime
from sqlmesh import ExecutionContext, model
@model(
"my_model.name",
columns={
"column_name": "int",
},
)
def execute(
context: ExecutionContext,
start: datetime,
end: datetime,
execution_time: datetime,
**kwargs: t.Any,
) -> pd.DataFrame:
...
According to the sqlmesh documentation, Python models come in two different forms:
- A model that returns a dataframe (e.g. pandas, pyspark, snowpark)
- A model that returns a sqlglot expression (
sqlglot.exp.Expression)
These models are discovered by sqlmesh's loader as long as the model exists in
the models directory of a sqlmesh project.
Python Models and Factory Functions
Since python models are simply python code the sqlmesh loader will simply
execute any python modules in the models directory. This then allows for a
factory pattern with regards to sqlmesh python models. This is a basic example:
def model_factory(values: list[str]):
@model(
f"my_model.{values}_model",
columns={
"column_name": "int",
},
)
def execute(
context: ExecutionContext,
start: datetime,
end: datetime,
execution_time: datetime,
**kwargs: t.Any,
) -> pd.DataFrame:
...
In this example, the factory takes an input of values which is just a list of
strings. If Used like this:
# Instantiate the factory
model_factory(["foo", "bar", "baz"])
We would then generate my_model.foo_model, my_model.bar_model, and
my_model.baz_model.
This contrived example isn't all that useful but if you can imagine that the
values parameter could be derived in any way that python allows, it opens up
possibilities. On it's own this might not seem useful but this pattern is the
building block of the time series metrics factory.
SQLGlot Rewriting
With the timeseries metrics factory we take advantage of the fact that sqlglot can handle semantic rewriting to do some fairly powerful transformations for when generating metrics models. Take for example the following sql:
SELECT e.id as id, e.name as name FROM employees as e
When parsed by SQLGlot using sqlglot.parse_one we get the following AST.
Select(
expressions=[
Alias(
this=Column(
this=Identifier(this=id, quoted=False),
table=Identifier(this=e, quoted=False)),
alias=Identifier(this=id, quoted=False)),
Alias(
this=Column(
this=Identifier(this=name, quoted=False),
table=Identifier(this=e, quoted=False)),
alias=Identifier(this=name, quoted=False))],
from=From(
this=Table(
this=Identifier(this=employees, quoted=False),
alias=TableAlias(
this=Identifier(this=e, quoted=False)))))
Given this object representation, we can actually use sqlglot to rewrite the
source_table to point to an entirely different source table. If we wished to
instead use updated_employees as the source table that's something we can do
like this:
from sqlglot import parse_one, exp
query = parse_one("SELECT e.id as id, e.name as name FROM employees as e")
updated_table_name_query = exp.replace_tables(query, {"employees": "updated_employees"})
More interestingly, let's say we wanted to use the employees but instead of
getting just the id of a given employee in the source_table we also want to
get the department name by joining on the departments table. Let's pretend that
the employees table also has department_id as an available column.
We could do this transform as follows:
# The top level expression is a `sqlglot.exp.Select` expression.
# This has the columns in the `expressions` property. Ideally,
# we'd actually want to wrap this in a function that doesn't update
# this in place so we can preserve the original query, but for simplicity
# we simply do this for now.
query.expressions.append(exp.to_column("d.department_name").as_("department_name"))
# To add the join we simply add it to the parsed object.
# Notice we need to have query on the left side of the equal sign.
# This is because the `join()` method does not update the original
# object in place.
query = query.join(
exp.to_table("departments").as_("d"),
on="d.department_id = e.department_id",
join_type="inner"
)
And this would generate the following SQL:
SELECT
e.id AS id,
e.name AS name,
d.department_name AS department_name
FROM employees AS e
INNER JOIN departments AS d
ON d.department_id = e.department_id
The Time Series Metrics Factory
The time series metrics factory is a factory function that generates a collection of models based on a configuration that effectively parameterizes any query that performs some kind of aggregation. The parameterizations, at this time, are limited to different entity relationships or time aggregations (either normal time buckets or rolling windows). Combined, this allows us to generate a large number of models from a single query definition. Additionally, the generated models are combined in various ways to provide additional metadata for the OSO frontend.
We implemented this models metrics factory as a way to keep the data warehouse as DRY as possible. More code means more maintenance and given the power available in sqlmesh and sqlglot to enable semantic transformations, we would reduce lines of code significantly.
Key Components
The following Entity Relationship diagram gives a general overview of the architecture of the time series metrics factory:
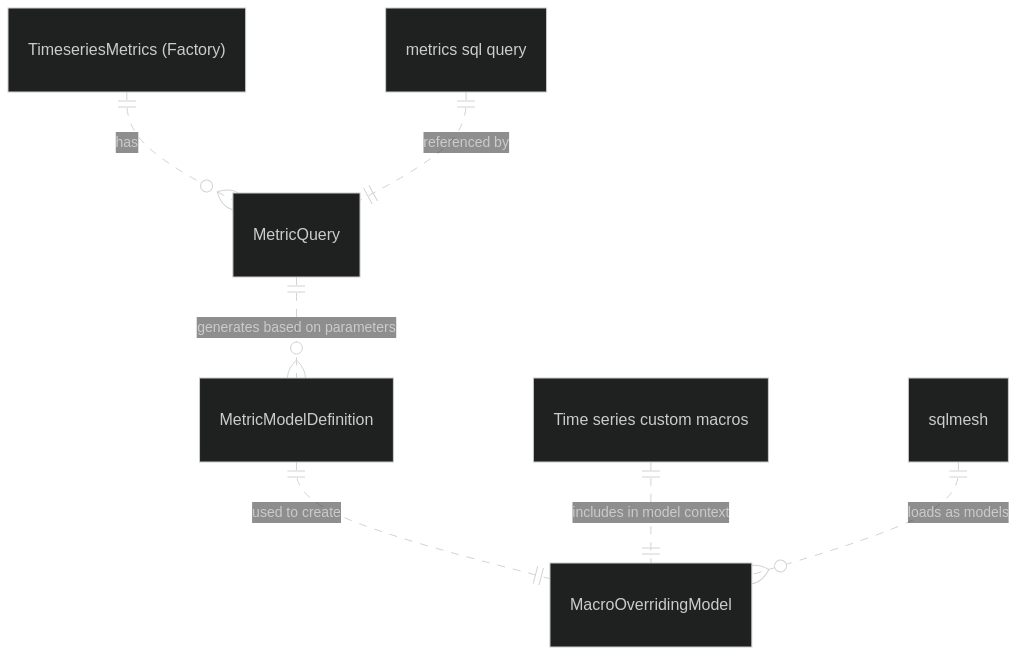
The key components of the diagram are:
TimeseriesMetrics (Factory)- This is the factory class that is defined in
warehouse/metrics_tools/factory/factory.py. This should generally be instantiated from sqlmesh using thetimeseries_metricsfunction.
- This is the factory class that is defined in
MetricQuery- This is used to define any parameters that should associated with a given
metric. This needs a reference to a metrics sql query from
warehouse/oso_sqlmesh/oso_metrics. This is defined by theMetricQueryDefobject when instantiating aTimeseriesMetricsclass.
- This is used to define any parameters that should associated with a given
metric. This needs a reference to a metrics sql query from
MetricModelDefinition- This object defines a single metric model that the factory generates. It is all the parameters specific to that single model and includes any rendered sql that is used to execute the model's query.
Time series custom macros- These are special macro functions that are injected into each of the models for things like proper time boundaries and sample dates.
MacroOverridingModel- This is a special class we created to override the macros of the generated sqlmesh models.
Rendering SQL for each metric model
The majority of the interesting parts of the metrics factory happen inside the rendering of each of the metric models.
Each of the metrics models has a set of parameters. For example, given the
following MetricsQueryDef:
"stars": MetricQueryDef(
ref="code/stars.sql",
time_aggregations=[
"daily",
"weekly",
],
entity_types=["artifact", "project"],
),
You'd end up with 4 different metrics models:
- Entity Type =
artifact- Time Aggregation =
daily - Time Aggregation =
weekly
- Time Aggregation =
- Entity Type =
project- Time Aggregation =
daily - Time Aggregation =
weekly
- Time Aggregation =
We then iterate through each of these different parameters and generate the
associated sql for each of these models. We use a special joining transformation
that is defined in warehouse/metrics_tools/joiner to handle the entity type
parameters and the injected macros for each of the models handles the proper
time bucketing by utilizing a @time_aggregation that is injected to the
model's sqlmesh context.
A note on SQLMesh's customized python function serialization
This is not something you will find much documentation on in the official sqlmesh docs but sqlmesh's state system is powerful because it has the ability to track changes to both sql and python models. Part of how it achieves this is that it stores python models in a special serialized format. This also means that it can use the serialized python to perform it's "runs" of any given sqlmesh model in a way that is properly versioned (for the most part).
For our purposes, we actually try to use what we call proxies (see
warehouse/metrics_tools/factory/proxy) because the sqlmesh storing the
serialized python is a bit too sensitive to change. This might not always be
what we want in the future as changes in the code could should likely cause
changes in the model but this was done because many of the generated metrics
models rely on the same code so changing a one small thing could cause breaking
changes. In the future we might avoid this by simply setting all metrics models
to be forward only (this is now the default setting).